Real Time And Distributed System
A real-time system is any information processing system which has to respond to externally generated input stimuli within a finite and specified period – the correctness depends not only on the logical result but also the time it was delivered – failure to respond is as bad as the wrong response!
- Hard real-time systems
- Soft real-time systems
- Firm teal-time systems
- Weakly hard real-time
- A deadline is a given time after a triggering event, by which a response has to be completed.
- Therac 25 example
what is a need fo rtos
- Fast context switches? – should be fast anyway
- Small size? – should be small anyway
- Quick response to external triggers? – not necessarily quick but predictable
- Multitasking? – often used, but not necessarily
- “Low Level” programming interfaces? – might be needed as with other embedded systems
- High processor utilisation? – desirable in any system (avoid oversized system)
Hard real-time systems
- An overrun in response time leads to potential loss of life and/or big financial damage
- Many of these systems are considered to be safety critical.
- Sometimes they are “only” mission critical, with the mission being very expensive.
- In general there is a cost function associated with the system.
Soft real-time systems
- Deadline overruns are tolerable, but not desired.
- There are no catastrophic consequences of missing one or more deadlines.
- There is a cost associated to overrunning, but this cost may be abstract.
- Often connected to Quality-of-Service (QoS)
Firm teal-time systems
- The computation is obsolete if the job is not finished on time.
- Cost may be interpreted as loss of revenue.
- Typical example are forecast systems.
Weakly hard real-time systems
- Systems where m out of k deadlines have to be met.
- In most cases feedback control systems, in which the control becomes unstable with too many missed control cycles.
- Best suited if system has to deal with other failures as well (e.g. Electro Magnetic Interference EMI).
- Likely probabilistic guarantees sufficient.
Classification Of Real-Time Systems
Real-Time systems can be classified [Kopetz97] from different perspectives. The first two classifications, hard real-time versus soft real-time, and fail-safe versus fail-operational, depend on the characteristics of the application, i.e., on factors outside the computer system. The second three classifications, guaranteed-timeliness versus best-effort, resource-adequate versus resource-inadequate, and event-triggered versus time-triggered, depend on the design and implementation, i.e., on factors inside the computer system. However this paper focuses on the differences between hard and soft real-time classification.
Hard Real-Time versus Soft Real-Time
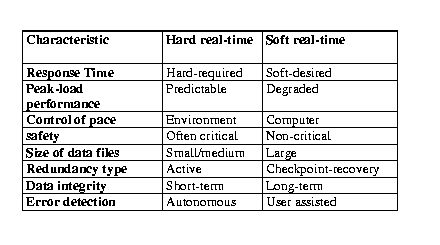
Tabel 1 shows the major differences between hard and soft real-time systems. The response time requirements of hard real-time systems are in the order of milliseconds or less and can result in a catastrophe if not met. In contrast, the response time requirements of soft real-time systems are higher and not very stringent. In a hard real-time system, the peak-load performance must be predictable and should not violate the predefined deadlines. In a soft real-time system, a degraded operation in a rarely occurring peak load can be tolerated. A hard real-time system must remain synchronous with the state of the environment in all cases. On the otherhand soft real-time systems will slow down their response time if the load is very high. Hard real-time systems are often safety critical. Hard real-time systems have small data files and real-time databases. Temporal accuracy is often the concern here. Soft real-time systems for example, on-line reservation systems have larger databases and require long-term integrity of real-time systems. If an error occurs in a soft real-time system, the computation is rolled back to a previously established checkpoint to initiate a recovery action. In hard real-time systems, roll-back/recovery is of limited use.
Real-Time Scheduling
A hard real-time system must execute a set of concurrent real-time tasks in a such a way that all time-critical tasks meet their specified deadlines. Every task needs computational and data resources to complete the job. The scheduling problem is concerned with the allocation of the resources to satisfy the timing constraints. Figure 2 given below represents a taxonomy of real-time scheduling algorithms.
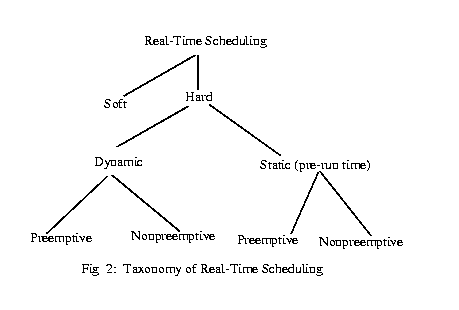
Real-Time scheduling can be categorized into hard vs soft. Hard real-time scheduling can be used for soft real-time scheduling. Some of the research on QoS [ Klara95] addresses this problem in detail and is not covered here. The present paper focuses on scheduling algorithms for hard real-time.
Hard real-time scheduling can be broadly classifies into two types: static and dynamic. In static scheduling, the scheduling decisions are made at compile time. A run-time schedule is generated off-line based on the prior knowledge of task-set parameters, e.g., maximum execution times, precedence constraints, mutual exclusion constraints, and deadlines. So run-time overhead is small. More details on static scheduling can be found in [ Xu90]. On the otherhand, dynamic scheduling makes its scheduling decisions at run time, selecting one out of the current set of ready tasks. Dynamic schedulers are flexible and adaptive. But they can incur significant overheads because of run-time processing. Preemptive or nonpreemptive scheduling of tasks is possible with static and dynamic scheduling. In preemptive scheduling, the currently executing task will be preempted upon arrival of a higher priority task. In nonpreemptive scheduling, the currently executing task will not be preempted until completion.
Dynamic Scheduling Algorithms
Schedulability test often used by dynamic schedulers to determine whether a given set of ready tasks can be scheduled to meet their deadlines. Different scheduling algorithms and their schedulability criteria is explained below.
Rate Monotonic Algorithm (RMA)
Rate monotonic algorithm [ Lui94] is a dynamic preemptive algorithm based on static priorities. The rate monotonic algorithm assigns static priorities based on task periods. Here task period is the time after which the tasks repeats and inverse of period is task arrival rate. For example, a task with a period of 10ms repeats itself after every 10ms. The task with the shortest period gets the highest priority, and the task with the longest period gets the lowest static priority. At run time, the dispatcher selects the task with the highest priority for execution. According to RMA a set of periodic, independent task can be scheduled to meet their deadlines, if the sum of their utilization factors of the n tasks is given as below.

Ealriest Deadline-First (EDF) Algorithm:
EDF algorithm is an optimal dynamic preemptive algorithm based on dynamic priorities. In this after any significant event, the task with the earliest deadline is assigned the highest dynamic priority. A significant event in a system can be blocking of a task, invocation of a task, completion of a task etc. The processor utilization can up to 100% with EDF, even when the task periods are not multiples of the smallest period. The dispatcher operates in the same way as the dispatcher for the rate monotonic algorithm.
The Priority Ceiling Protocol:
The priority ceiling protocol [ Lui90] is used to schedule a set dependant periodic tasks that share resources protected by semaphores. The shared resources, e.g., common data structures are used for interprocess communication. The sharing of resources can lead to unbounded priority inversion. The priority ceiling protocols were developed to minimize the priority inversion and blocking time.
Static Scheduling Algorithms
In static scheduling, scheduling decisions are made during compile time. This assumes parameters of all the tasks is known a priori and builds a schedule based on this. Once a schedule is made, it cannot be modified online. Static scheduling is generally not recommended for dynamic systems. Applications like process control can benefit from this scheduling, where sensor data rates of all tasks are known before hand. There are no explicit static scheduling techniques except that a schedule is made to meet the deadline of the given application under known system configuration. Most often there is no notion of priority in static scheduling. Based on task arriaval pattern a time line is built and embedded into the program and no change in schedules are possible during execution.
Distributed System
Distributed system a system in which components are distributed across multiple locations and computer-network.
Today’s information systems are no longer monoUdl.ic, m.alnf.rame computer-based system . Instead, they are built on some combination of networks to form distributed systems. A distributed system is one in which the components of an information system are distributed to multiple locations in a computer network. Accordingly, the processing workload required to support these components Is also distributed across multiple computers on the network.
The opposite of distributed systems are centralized systems. In centralized systems, a central, multi user computer (usually a mainframe) hosts all components of an information system. The users interact with this host computer via terminals (or, today, a PC emulating a terminal), but virtually all of the actual processing and work Is done on the host computer.
Distributed systems are Inherently more complicated and more difficult to implement than centralized solutions. So why is the trend toward distributed systems?
- Modem businesses are already distributed, and, thus, they need distributed system solutions.
- Distributed computing moves information and services closer ro the customers that need them.
- Distributed computing consolidates the incredible power resulting from the proliferation of personal computers across an enterprise (and society in general). Many of these personal computers are only used to a fraction of their processing potential when used as stand-alone PCs.
- In general, distributed system solutions are more user.frlendly because they use the PC as the user interface processor.
- Personal computers and network servers are much Jess expensive than main-frames. (But admittedly)', the total cost of ownership is at least as expensive once the networking complexities are added ln.)
There is a price to be paid for distributed systems. Network data traffic can cause congestion that actually slows performance. Data security and Integrity can also be more easily compromised In a distributed solution. Still there Is no arguing the trend toward distributed systems architecture. While many centralized, legacy applications still exist, they are gradually being transformed Into distributed Information systems. Conceptually, any information system application can be mapped to the layers:
- The presentation layer is the actual user interface- the presentation of inputs and outputs ro the user.
- The presentation logic layer is any processing that must be done to generate the presentation. Examples include editing input data and formatting output data.
- The application logic layer Includes all the logic and processing required to support the actual business application and rules. Examples include credit checking, calculations, data analysis.
- The data manipulation layer includes all the commands and logic required to store and retrieve data to and from the database.
- The data layer is the actual stored data in a database.
There are three types of distributed systems architecture:
- File server architecture.
- client/server architecture.
- internet-based architecture.
File Server Architecture : Today very few personal computers and workstations are used to support standalone information systems. Organizations need to share data and services. Local area networks allow many PCs and workstations to be connected to share resources and communicate with one another. A local area network (lAN) is a set of client computers (usually PCs) connected to one or more servers (usually a more powerful PC or larger computer) through either cable or wireless connections over relatively short distances - for Instance, in a single department or In a single building.
Client/Server Architectures : The prevailing distributed computing model of the current era Is called client/server computing (although it Is rapidly giving way to lnternet-based models). A client/server system is a solution in which the presentation, presentation logic, application logic, data manipulation, and data layers are distributed between client PCs and one or more servers.
The client computers may be any combination of personal computers or work-stations, “sometimes connected” notebook computers, handheld computers (e.g.,Palm or Windows Mobile Platforms), WebTVs, or any devices with embedded processors that could connect to the network (e.g., robots or controllers on a manufacturing shop floor). clients may be thin or fat. A thin client is a personal computer that does not have to be very powerful (or expensive) ht terms of processor speed and memory because it only presents the Interface (screens) to the user-in other words, it acts only as a terminal. Examples include Remote Desktop and X/Windows. In thin client computing, the actual application logic executes on a remote application server. A fat client Is a personal computer, notebook computer, or workstation that is typically more powerful (and expensive) In terms of processor speed, memory, and storage capacity. Almost all PCs are considered fat clients.
Internet – Based Computing Architectures : Some consider Internet-based system architectures to be the Latest evolution of client/server. We present internet-based computing alternatives this section as a fundamentally different form of distributed architecture that Is rapidly reshaping the design thought processes of systems analysts and Information technologists. A network computing system is a multi tiered solution In which the presentation and presentation logic layers are implemented in client – side Web browsers using content downloaded from a web server. The presentation logic layer then connects to the application logic layer that runs on an application server, which subsequently connects to the database server(s) on the backside. Think about tt! All information systems running in browsers- financials, human resources, operations- all of them! . E-commerce is part of this formula, and as we go to press, e-commerce applications are getting most of the attention. But the same internet technology being used to build e-commerce solutions are being used to reshape the internal information systems of most businesses- we call it e-business (although that term Is also subject to multiple Interpretations). Network computing Is, in our view, a fundamental shift away from what we Just described as client/server.
Advantages of Distributed system :
- Economics: cost effective way to increase computing power.
- Speed: a distributed system may have more total computing power than a mainframe.
- Ex. 10,000 CPU chips, each running at 50 MIPS. Not possible to build 500,000 MIPS single processor since it would require 0.002 nsec instruction cycle.
- Reliability: If one machine crashes, the system as a whole can still survive. Higher availability and improved reliability.
- Incremental growth: Computing power can be added in small increments. Modular expandability
- Data sharing: allow many users to access to a common data base
- Resource Sharing: expensive peripherals like color printers
- Communication: enhance human-to-human communication, e.g., email, chat
- Flexibility: spread the workload over the available machines
Disadvantages of Distributed System :
- Software: difficult to develop software for distributed systems
- Network: saturation, lossy transmissions
- Security: easy access also applies to secrete data
reference:
Frequently Asked Questions
Recommended Posts:
- Difference Between Manual And Automated System - Manual System vs Automated System
- Scope and classification of metrics
- Software measuring process and product attributes
- Direct and Indirect Measures, Reliability
- What Is Information Systems Analysis and Design?
- CHARACTERIZATION OF DISTRIBUTED SYSTEMS
- Examples of distributed systems
- Web search
- Selected application domains and associated networked applications
- Massively multiplayer online games (MMOGs)
- Financial trading
- Trends in distributed systems
- Pervasive networking and the modern Internet
- Mobile and ubiquitous computing
- Distributed multimedia systems